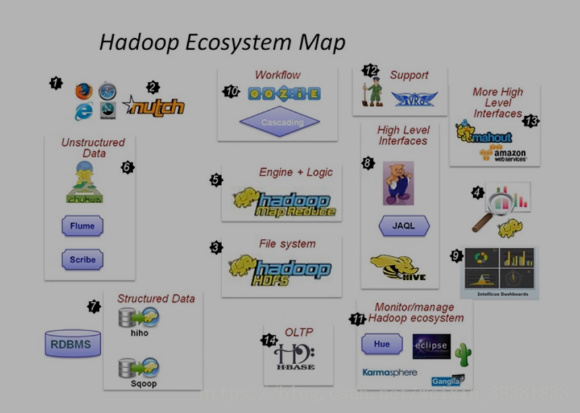
现在的大数据已经成为了Hadoop生态的天下
HIVE

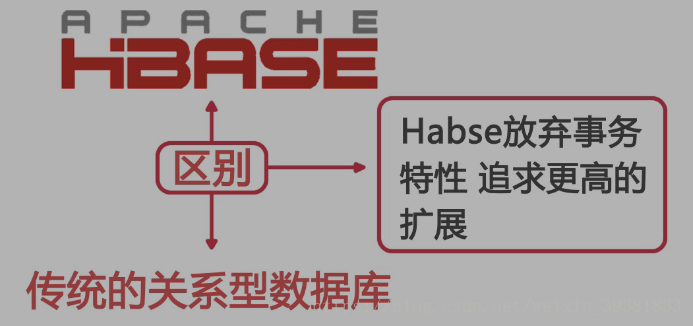
HABSE :存储结构化数据的分布式数据库
和传统关系型数据库不同:放弃事物特性 追求高拓展
 和HDFS对比:数据的随机读写和实时访问读写
和HDFS对比:数据的随机读写和实时访问读写 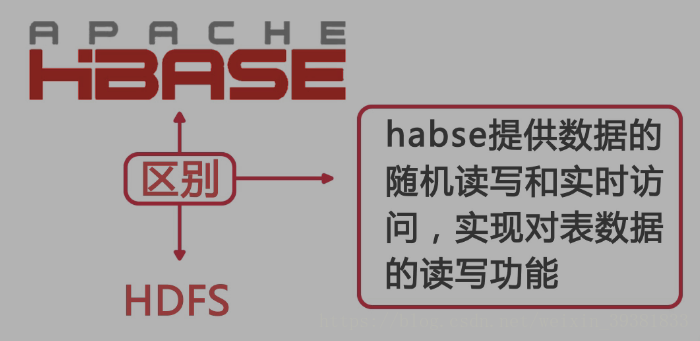
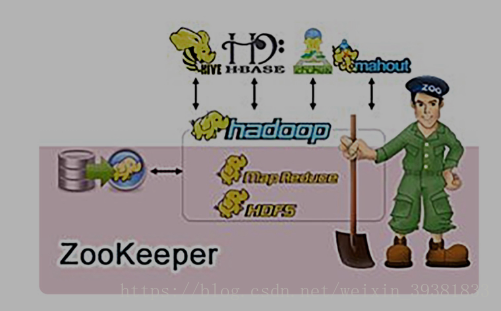
zookeeper
管理Hadoop平台每个node的状态
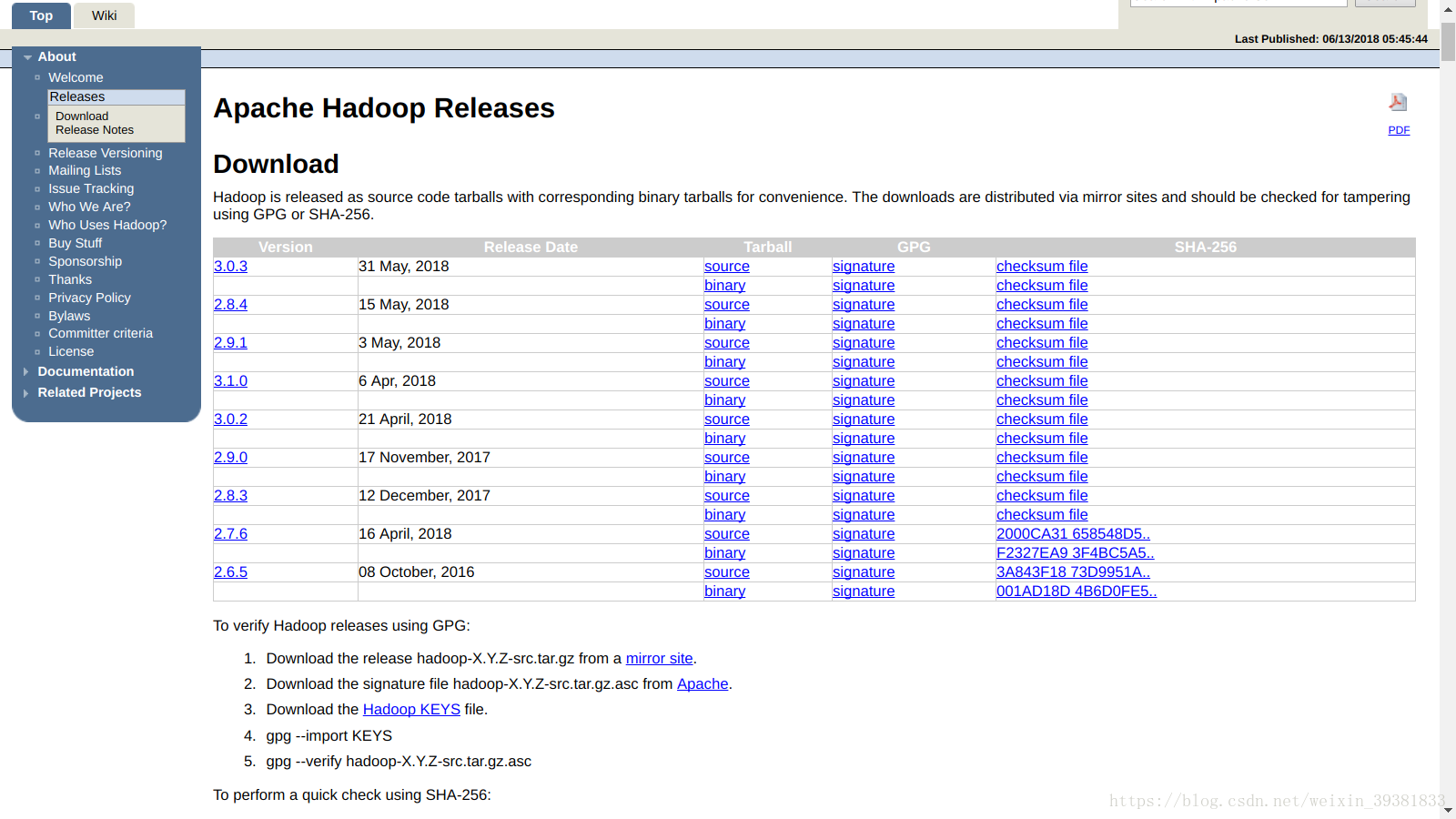
Hadoop版本
目前(18.7)已经到了3+版本,和ver1.x ver2.x还有很大的差别的
本文共 275 字,大约阅读时间需要 1 分钟。
和传统关系型数据库不同:放弃事物特性 追求高拓展
和HDFS对比:数据的随机读写和实时访问读写 管理Hadoop平台每个node的状态
目前(18.7)已经到了3+版本,和ver1.x ver2.x还有很大的差别的
转载于:https://www.cnblogs.com/oifengo/p/9385940.html